As part of Tufts University‘s Graduate Student Retreat, I presented a short, 30-minute Introduction to Text Analysis in the Data Lab.
Interested in learning more? Check out the slides below!
As part of Tufts University‘s Graduate Student Retreat, I presented a short, 30-minute Introduction to Text Analysis in the Data Lab.
Interested in learning more? Check out the slides below!
On May 18th, I had the honor of giving a talk at Trinity College as part of their Spring Institute for Teaching & Technology.
Below are the slides from my presentation:

Today, I gave a talk for the Yale DH Lab on two of my Digital Victorian Studies classes: “Digital Tools for the 21st Century: Sherlock Holmes’s London” and “Virtually London: Literature and Laptops.”
Ahmed Seddik kindly videotaped the talk, which you can see here: https://t.co/NfuSWKbDLY
If you’d like to see the slides, you can view them below:
I’m happy to announce that I am now on the NINES Executive Council as the Head of Pedagogical Outreach! I’m honored by this new position, and I’m eager to start!
In the coming weeks and months, I hope to do a survey of how the projects NINES has peer-reviewed are used in classes and start creating a repository of lesson plans and assignments.
To start us off, here is an example of how I’ve used the crowd-sourcing project Book Traces in the classroom. For anyone who hasn’t yet used it, Book Traces is a site, sponsored by NINES, that collects 19th century marginalia from 19th century books located in the stacks (not special collections) of university libraries. Participants then photograph these examples of marginalia and upload them into the site to create an archive of readers’ markings in texts, helping scholars examine how actual Victorian readers responded to literature. In my introduction to digital humanities class, my students first read articles about Book Traces, then met with librarian Stephan Macaluso, who explained how to recognize different types of 19th century handwriting (Copperplate, Spencerian, and Palmer) and writing implements (steel-nip and fountain pen) so they could figure out which marginalia would meet the assignment requirements. Armed with this knowledge, we let them loose in the stacks. Even though SUNY New Paltz’s library only contains about 2000 books from the 19th century, most of my students were able to find examples to upload into Book Traces, and in fact, they uploaded the 400th unique volume into the site. Here are some of their most interesting discoveries:

One student found a handwritten letter in German from 1897 attached to the inside cover of Johann Gustav Droysen’s Principles of History, which was translated from the original German into English by E. Benjamin Andrews. The letter appears to be from the writer to the translator, giving him permission to translate the book into English.
 Another student found the book Shakespeare: The Man and his Stage with the inscription “To Barry Lupino . . . .a souvenir, Theatre Royal Huddenfield, July 16, 1923 from Alfred Wareing”: with some research, she was able to determine that Lupino was a British actor, and Wareing, a theatrical producer with a reputation for producing demanding productions and creating the Theatre Royal.
Another student found the book Shakespeare: The Man and his Stage with the inscription “To Barry Lupino . . . .a souvenir, Theatre Royal Huddenfield, July 16, 1923 from Alfred Wareing”: with some research, she was able to determine that Lupino was a British actor, and Wareing, a theatrical producer with a reputation for producing demanding productions and creating the Theatre Royal.
Book Traces gets students into the library, encourages them to rethink their definition of a book, and engages them in a large-scale scholarly project, while showing them that research can be fun. If you’d like to do an assignment like this in one of your classes, feel free to use my assignment as a model: https://hawksites.newpaltz.edu/dhm293/online-assignment-3-book-traces/
If you have assignments using digital projects that NINES has peer-reviewed, or if you have other ideas as to how NINES can bolster its pedagogical mission, please email, tweet, or comment on this post!
I look forward to hearing from all of you!
Tools:
Voyant: http://voyant-tools.org/
Word Tree: https://www.jasondavies.com/wordtree/
Roaring ‘Twenties: http://vectors.usc.edu/projects/index.php?project=98
Women Who Rock: Making Scenes, Building Communities: http://content.lib.washington.edu/wwrweb/index.html
Old Bailey Online: http://www.oldbaileyonline.org/
Sacred Centers in India: http://sci.dhinitiative.org/
19th Century Disability Studies: http://www.nineteenthcenturydisability.org/
Tool:
Omeka: https://www.omeka.net/
Invasion of America: http://invasionofamerica.ehistory.org/
Spread of Slavery: http://lincolnmullen.com/projects/slavery/
Mapping SUNY New Paltz: https://sunynpmap.wordpress.com/our-mapping-project/
Tools:
MapBox: https://www.mapbox.com/
Google Maps: http://maps.google.com
Rowan University Library’s Digital Humanities page: http://libguides.rowan.edu/content.php?pid=629874&sid=5210913
DiRT (Digital Research Tools) Directory: http://dirtdirectory.org/
Digital Humanities Questions and Answers: http://digitalhumanities.org/answers/
Visualizations:
Voyant: http://voyant-tools.org/
Editions:
Lyrical Ballads: http://archive.rc.umd.edu/editions/LB/html/Lb98-b.html
Hypertext edition of Tintern Abbey: http://bruce.personal.asu.edu/tintern/content/why-tintern-abbey
Archives:
Tintern Abbey and Romantic Tourism in Wales: http://www.lib.umich.edu/enchanting-ruin-tintern-abbey-romantic-tourism-wales/images.html
Bonus Archive:
Shelley-Godwin Archive: http://shelleygodwinarchive.org/
GIS (Geographic Information System):
Mapping the lakes: http://www.lancaster.ac.uk/mappingthelakes/
Online Journals/Publications:
RaVon: http://ravonjournal.org/
BRANCH: http://www.branchcollective.org/
Romantic Circles: http://www.rc.umd.edu/
3D modeling:
Tintern Abbey Model: http://www.virtualexperience.co.uk/?page=projects&sub=tintern
Gamification:
“Tintern Abbey First-Person Shooter”: https://scratch.mit.edu/projects/10764/
Explanation of Game: http://liu.english.ucsb.edu/wiki2/index.php/Instructor%27s_Project#Project_Concept
There’s been a flurry of activity on the continuing question of Matt Jockers’ Syuzhet package that purports to use sentiment analysis and a low-pass filter to find the “six, or possibly seven, archetypal plot shapes” (also known as foundation shapes) in any novel.[1] Matt[2] wrote a new blog post defending his tool and claiming that my testing framework, which demonstrated that foundation shapes don’t “always reflect the emotional valence of novels,” actually proved the success of his tool. This blog post will respond to that claim as well as to recent comments by Andrew Piper on questions of how we validate data in the Humanities.
First, though, let’s start with Matt’s most recent post. Matt claims that Syuzhet’s purpose is to “approximat[e] the fundamental highs and lows of emotional valence” in a novel. Unfortunately, by his own criteria, Syuzhet fails. This is not a matter of opinion and it is something we can test.
Matt used a method I’d suggested—changing the emotional valence of sections of a novel to 0 (neutral emotion)—to generate foundation shapes for variants on Portrait of the Artist. Although he cites these images as evidence of the success of Syuzhet, they actually prove just how broken Syuzhet is. For example, he “neutralizes” the sentiment for the final third of Portrait of the Artist, observes that the foundation shape is essentially unchanged, points out the original novel’s emotional valence was essentially neutral, and claims that this is proof that the foundation shapes work correctly: “So all we have really achieved in this test is to replace a section of relatively neutral valence with another segment of totally neutral valence.” He’s right that in both cases, the final third of the signal has mostly neutral valence: however, he overlooks the fact that the foundation shape doesn’t.
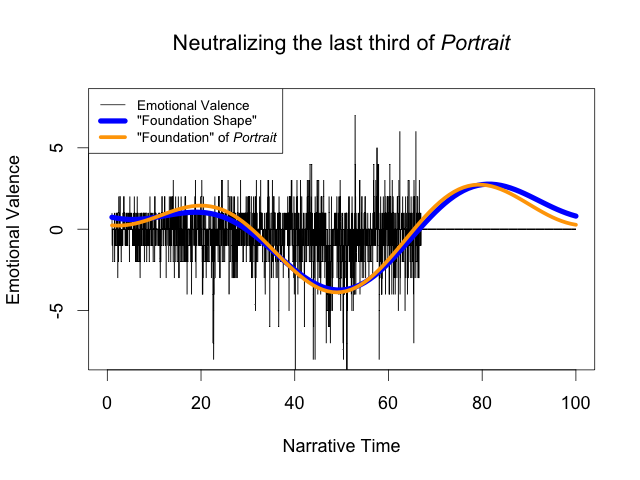 Instead of being a flat line, it rises substantially, which should only occur for positive sentiment. If Syuzhet is designed to “approximat[e] the fundamental highs and lows of emotional valence,” then it fails dramatically, because the “high” in the altered Portrait of the Artist should not appear in a section of neutral sentiment.
Instead of being a flat line, it rises substantially, which should only occur for positive sentiment. If Syuzhet is designed to “approximat[e] the fundamental highs and lows of emotional valence,” then it fails dramatically, because the “high” in the altered Portrait of the Artist should not appear in a section of neutral sentiment.
Matt again misses the point of my testing algorithm when he artificially raises and lowers the emotion at the end of the novel: while he correctly notes that raising or lowering the emotion of the end of the novel causes the foundation shape at the end to also raise or lower, he fails to notice that this also alters the earlier parts of the foundation shape to make it incorrect. In fact, simply changing the final third of the story causes the relative highs and lows of the first two-thirds to be completely inverted:
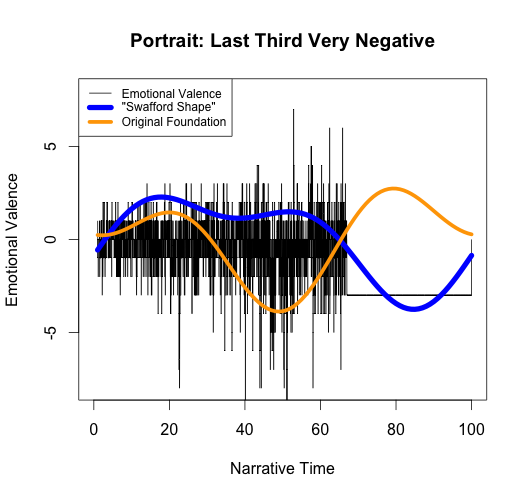
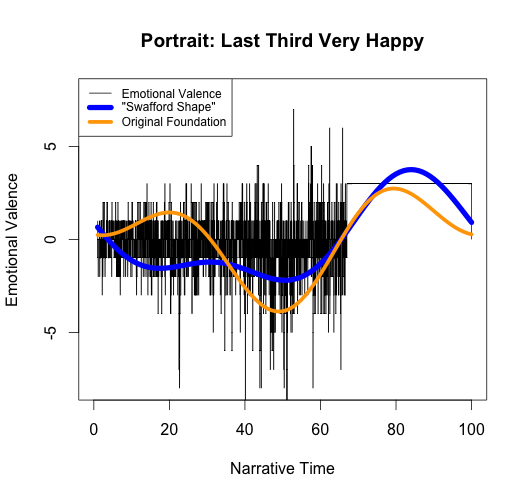
If the foundation shape truly reflected the emotional valence of the novel, it wouldn’t invert where the text remains the same. Yet again, it fails to “approximate the fundamental highs and lows of emotional valence.”
Matt then claims that “If we remove the most negative section of the novel, then we should see the nadir of the simple shape shift to the next most negative section.” This is true, but it also highlights the failure of the algorithm: as we see in the “Neutralized Middle” graph, the second-lowest point of the raw sentiment (around x=20) was the second-highest point of the original foundation shape (shown here in orange):
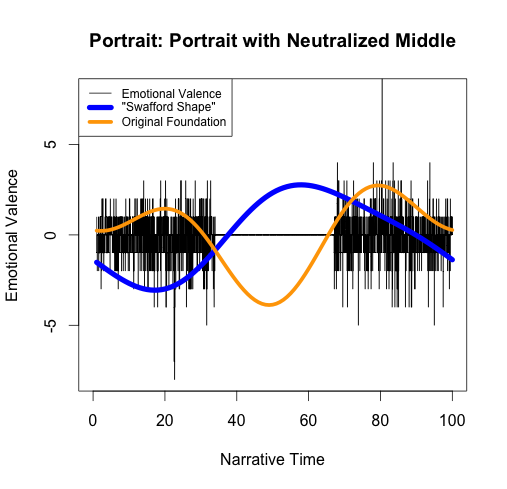
Obviously this is not estimating the “highs and lows” of the story – it’s finding one low and ignoring the rest. Of course, if we define success for Syuzhet as “it identifies the single highest or lowest point in a story,” then we could call the above figure a success as Matt claims, but if this is the goal then 1. It could have been done much more simply by just choosing the lowest point of the original sentiment, and 2. It’s a bad proxy for Vonnegut’s notion of “plot shape” because it can’t distinguish between multiple shapes that have similar lowest points.
The latter point is particularly problematic. The “Man in a Hole” plot shape is not the only one with a nadir in the middle: Vonnegut’s “Boy meets Girl” plot shape also has its greatest moment of negativity in the middle of the story.
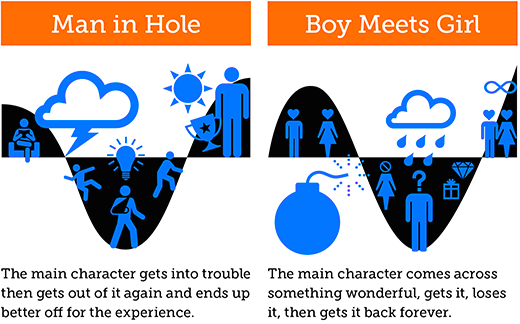
As a result, if we only at the lowest point only and consider rises or falls on either side irrelevant, as Matt does, then we can’t tell the differences between them. It’s also interesting to note that the foundation shape for Portrait of the Artist rises, falls, rises again, and falls again, which makes it much closer to a “Boy meets Girl” shape than the “Man in a Hole” that Matt continuously insists it is (though neither shape should have that final fall at the end). In short, the foundation shapes don’t just “miss some of the subtitles [sic]” in the data; they flat out distort it and introduce errors that in places make the foundation shape the opposite of the emotional trajectory.
Matt also objects to my using Syuzhet’s default value of 3 as the cutoff for the low pass filter for my graphs, stating that, as it is a “user tunable parameter,” it can be raised to reduce the ringing artifacts. I generated the examples with the default value because it is the number he used in his clustering, from which he concluded that there are only 6 or 7 plot shapes. Raising that number isn’t really a solution for two reasons: 1. It wouldn’t eliminate the ringing (ringing artifacts happen with any low-pass filter, though they’ll be smaller with higher cutoffs); and 2. It would require redoing all the clustering that led to these “archetypal” shapes, as the number and type of common plot shapes will likely be dramatically different with more terms.
Overall, there is no point in “seek[ing] to identify an ‘ideal’ number of components for the low pass filter,” because the low-pass filter is a poor choice for this resampling application: Gaussian blurring and a simple window average would be more successful because they would simplify the data without distorting it. In an earlier blog post, Matt justifies the low-pass filter instead of a simple window average (which he has already implemented as get_percentage_values) by claiming “You cannot compare [the results of get_percentage_values] mathematically because the amount of text inside each percentage segment will be quite different if the novels are of different lengths, and that would not be a fair comparison.” This suggests that he misunderstands the mathematics behind the low-pass filter he has implemented, because this statement is just as true of low-pass filtering as it is of get_percentage_values: each value in the result is a weighted average of the original values, and more text is averaged per data point in a longer novel than in a shorter one. If this really were an unfair comparison, then the entire Syuzhet project would be hopeless.
The errors with Syuzhet and this whole debate about whether or not it works relate to a larger question about validating a tool in the Humanities, which Andrew Piper touched on in his recent blog post: “Validation is not a process that humanists are familiar with or trained in. We don’t validate a procedure; we just read until we think we have enough evidence to convince someone of something.” Unfortunately, “read[ing] until we think we have enough evidence” doesn’t work with programming and science: programmers and scientists must actually design tests to make sure that the tools we build work as advertised. Building tools for distant reading therefore involves at least two types of validation: the first type requires making sure the tool works as expected, and the second type, possible only once the first type of validation works, requires analyzing the results of the tool to come up with new theories about history, literary history, or plot, or whatever the primary subject matter is for a given corpora. My blog posts have focused on the first type of validation: I have provided some sample tests where Syuzhet clearly fails, which means that we need to go back to fix the tool before we can take its output seriously and analyze it.
Fortunately, coming up with a way to perform the first type of validation for a Humanities tool is not as dire a problem as Andrew Piper suggested when he wrote “We can’t import the standard model of validation from computer science because we start from the fundamental premise that our objects of study are inherently unstable and dissensual.” As it turns out, the Humanities are not unique in studying the liminal or the multifaceted: many subfields of computer science struggle with “unstable” data all the time, from image processing to machine learning. True sentiment analysis scholars work on this problem: they acknowledge that words are polysemous, that language is nuanced and ambiguous, and that everyone reads texts differently. That’s why they use human-annotated corpora of texts, from which they can estimate how an “average” reader evaluates documents, to measure how well their algorithms approximate that “average” reader. We can actually learn a lot about addressing this problem by collaborating with our colleagues from outside the Humanities.
This brings me to my final point: Digital Humanities is best when we collaborate. As Humanists, we’ve been very well trained in our particular field (or fields, if we double-majored once upon a time), but we often haven’t been trained in things like statistics, sentiment analysis, or signal processing. We’re used to researching a wide variety of subjects, and that can take us pretty far, but we’re unlikely to fully understand all the nuances of the fields we try to learn on our own, especially if they usually require a PhD in physics or math. A quick conversation with a colleague in a different field goes a long way towards finding exciting solutions to confounding problems, but it’s not going to be enough to fully explain things like ringing artifacts or Fourier transforms. The only way to make sure that we’re not introducing problems we could never have anticipated with our limited knowledge is by assembling a team of experts. Before I posted my first response to Syuzhet, I sought input from people in a wide variety of fields—electrical engineers, software developers, mathematicians, and machine learning specialists—to make sure my critiques were valid, and I credited them in my post. Without collaborative teams comprised of scholars from a wide variety of fields, digital humanities scholarship will continue to be plagued by easily avoidable errors.
NOTES:
[1] While Ted Underwood has claimed that Syuzhet is entirely exploratory and no scholarly claims have been made, I will take Matt at his word and respond to the thesis he has posited in several blog posts and news articles.
[2] Matt Jockers informed me that he prefers to go by his first name, so I will happily oblige in this post.
[Update: Matthew Jockers posted a response to this critique yesterday. Rather than contribute to what he calls a “blogging frenzy,” and in the absence of a comments field on his blog, I will make a few points here:
1) It is clear that the Syuzhet package needs more peer review and rigorous testing — designed to confirm or refute hypotheses — before it will be possible to make valid claims about archetypal plot structures. I have attempted to model that testing and review here.
2) Matt seems to misunderstand my critique. I am not arguing about whether or not Portrait of the Artist represents a “man in a hole” plot shape; I’m pointing out that any Syuzhet plot shape can easily be the result of low-pass filter artifacts instead of a reflection of the computed sentiment (itself hard to analyze at the single word or sentence level), and that they therefore cannot yet be said to reliably reflect the emotional trajectories of novels.]
[This is a continuation of an ongoing dialogue about the Syuzhet package and literary text-mining. If you want to know the full history, check out Eileen Clancy’s Storify on the subject.]
[Update: The code that generates the graphs for this blog post is now available at https://github.com/jswafford/syuzhet-samples.]
A few weeks ago, Matthew Jockers published Syuzhet, an interesting package for the programming language R that uses sentiment analysis, together with a low-pass filter, to uncover one of “six, or possibly seven, archetypal plot shapes” (also known as foundation shapes) in any novel. Earlier this week, I posted a response, documenting some potential issues with the package, including problems with the sentence splitter, inaccuracies in the sentiment analysis algorithms, and ringing artifacts in the foundation shapes. A few days ago, Jockers responded; his newest blog post claims that while some of these problems do exist, they are limited to “one sentence here or one sentence there” and that in aggregate, the sentiment analysis succeeds. Jockers cites the apparent similarities in the emotional trajectories and foundation shapes produced with several different sentiment analysis algorithms on the same text as proof that Syuzhet is “good enough” that we can draw meaningful conclusions based on its foundation shapes.
This blog post investigates this claim, and draws two conclusions:
In his recent blog post, Jockers presents the emotional valences for Portrait of the Artist generated by Syuzhet’s four different sentiment analysis algorithms (left-hand graph), and the resulting foundation shapes (right-hand graph):
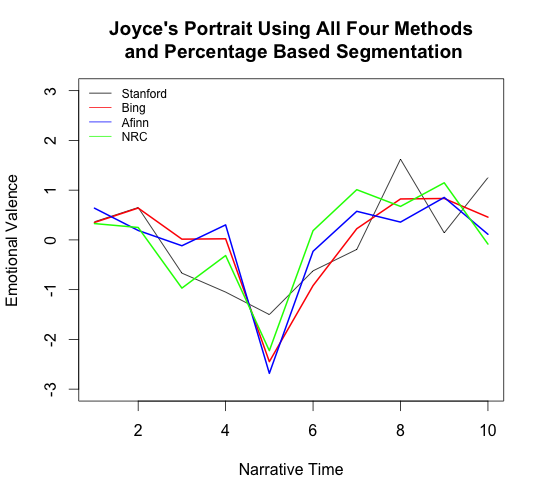
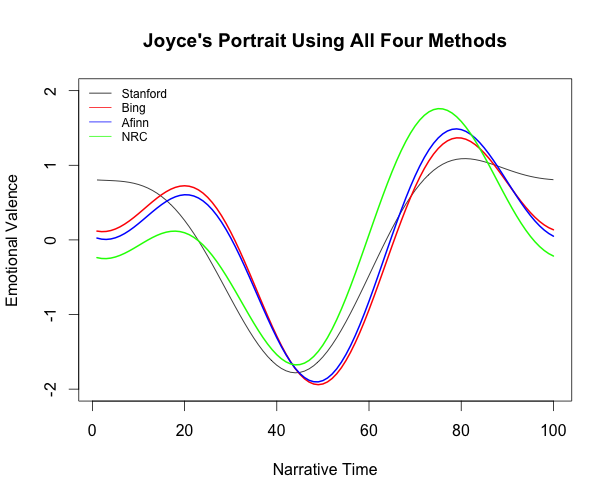
Although there are noticeable similarities between the four emotional valences in the graph on the left, they also have some significant differences, such as at x=8 where the Stanford line reaches its maximum while the Afinn and NRC lines drop downwards. And yet, these differences disappear in the foundation shapes on the right: all four curves reach their maximum around the 80% mark.
Jockers believes that these similar foundation shapes indicate that Syuzhet works, and that, despite the unreliability of the sentiment analysis, Syuzhet can still find the “latent emotional trajectory that represents the general sense of the novel’s plot.” I worried, though, that some of these similarities may be more due to ringing artifacts (which I discussed in my last post) than due to actual agreement between the different sentiment analysis methods.
Fortunately, there’s an easy way to test this: we can manually change the emotional valence for Portrait of the Artist and see if the foundation shape changes accordingly. For example, we can take the sentiment estimated by the bing method and simply set the valence for the final third of the novel to 0 (neutral sentiment): this is the equivalent of keeping the first two thirds of Portrait of the Artist the same, but changing the final third of the novel to consist of exclusively emotionless words. We would expect that the foundation shape would flatten out to 0 during the final third to reflect this change. Here’s what happens:
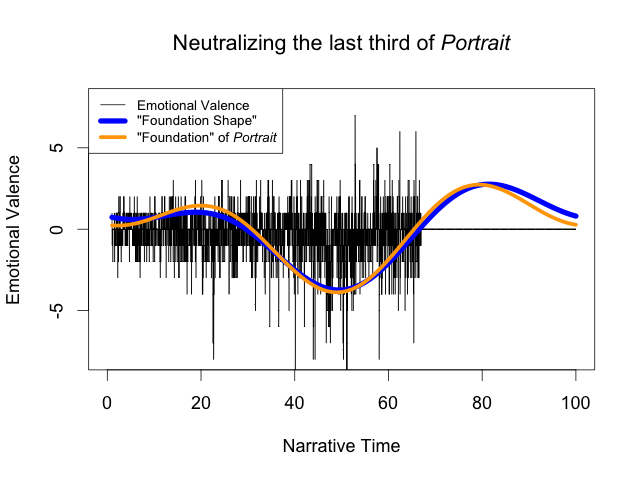
Surprisingly, the foundation shape is nearly identical: this suggests that the rise in the final third of the foundation shape is indeed a ringing artifact and not a result of an increase in positive emotion in the text.
In fact, we can take this even further: the foundation shape remains the same even if we make all but the middle twenty sentences of Portrait of the Artist neutral, leaving less than 0.5% of the novel unchanged:
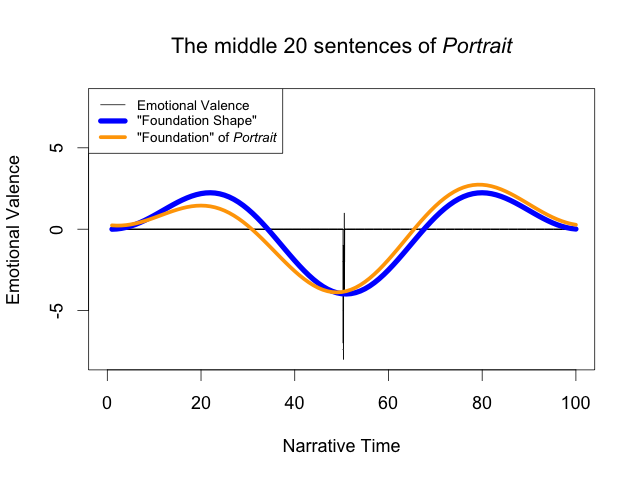
These observations cast Jockers’s comparison of the sentiment analyzers in a new light. Their similar foundation shapes do not validate Syuzhet’s sentiment analysis algorithm; they merely demonstrate that Syuzhet’s foundation shapes can make dissimilar curves similar.
This is not to say that the values at the ends never matter; as another experiment, I artificially raised the emotional valence of the opening and closing two-hundred sentences of Portrait of the Artist (about 8% of the novel), leaving the rest unchanged. This is the equivalent of changing the text of Portrait of the Artist so the opening and closing are extremely happy:
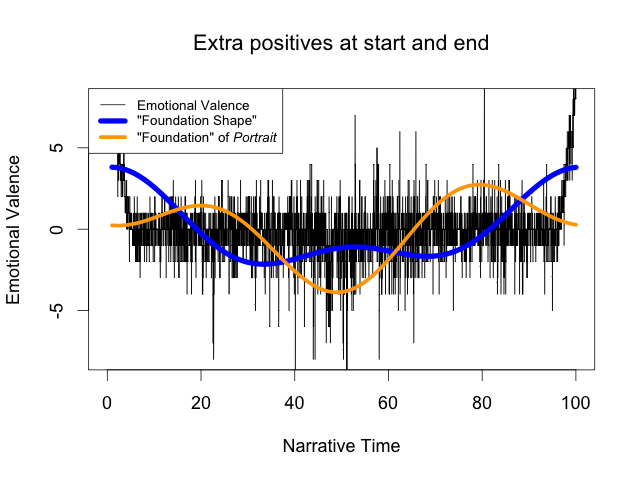
Interestingly, the new foundation shape (blue) now shows the midpoint of the novel as less negative than the area around it, even though it is still the most negative portion of the story (since we only changed the very beginning and end). This is a classic ringing artifact: the foundation shape can’t reflect the emotional heights at both ends of the story without altering the middle because the correct shape cannot be approximated by low-frequency sinusoids.
Since we’ve now seen several foundation shapes that don’t reflect the emotional valences that generated them, it’s reasonable to wonder just how dissimilar two graphs could be while still maintaining the same foundation shape. I asked Daniel Lepage (a professional programmer with a degree in mathematics) how we might find such graphs. He pointed out that Syuzhet computes foundation shapes by discarding all but the lowest terms of the Fourier transform. This means that stories where much of the emotional valence is determined by higher terms can have wildly different valences, yet still share a foundation shape. To test this, he created multiple signals—graphs of the emotional valences of hypothetical texts—that share the foundation shape of Portrait of the Artist (according to Syuzhet):
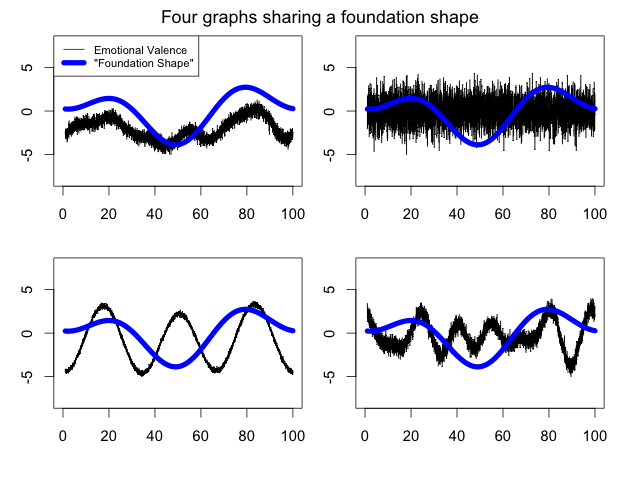
These sample signals clearly have very little in common with each other or with Portrait of the Artist, and yet they all produce completely identical foundation shapes, so a foundation shape may be entirely unlike the emotional trajectory of its novel.
The fourth example signal is particularly interesting: practically all of the variation is determined by the higher Fourier terms. This means that by making nearly-invisible low-frequency changes to the original valence, we can completely alter its foundation shape:
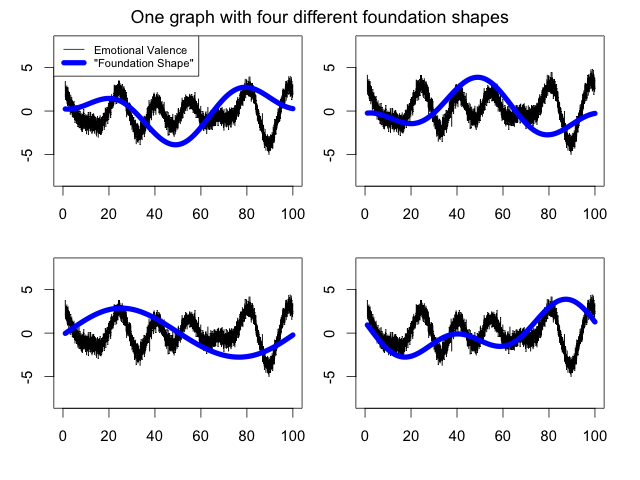
Obviously, this is a worst-case scenario: it is unlikely that a real book would perform quite so badly. Nonetheless, this proves that we cannot assume that Syuzhet’s foundation shapes reliably reflect the emotional trajectories of their novels.
Of course, the quality of the foundation shapes is a moot point unless we trust the underlying sentiment analysis. Jockers and I essentially agree on the worth of sentiment analysis as applied to novels: in his words, “Frankly, I don’t think any of the current sentiment detection methods are especially reliable.” All approaches—from the lexicon-based approaches to the more advanced Stanford parser—have difficulty with anything that doesn’t sound like a tweet or product review, which is not surprising. He and I have both shown a number of examples in which sentiment analysis fails to produce the emotional valence that a human would assign—such as “Well, it’s like a potato”—which suggests that modern sentiment analysis may not be up to the task of handling the emotional complexities of novels.
Although the Stanford parser does boast 80-85% accuracy, it was trained and tested on movie reviews, which do not generally have the same degrees of ambiguity and nuance as novels. The other three analysis methods Syuzhet provides are all based on word-counting; a cursory examination of modern sentiment analysis literature indicates that this hasn’t been the state of the art for quite some time. Even Bing Liu, creator of the Bing lexicon (Syuzhet’s default lexicon), states on his website that “although necessary, having an opinion lexicon is far from sufficient for accurate sentiment analysis.”[1]
Ultimately, however, this debate is skirting the real issue, which Lisa Rhody raised in a comment on my last blog post. She asked how “sentence-level errors in detecting sentiment present problems in the aggregate” and wondered “how these errors might build on themselves to continue to cause concern at scale.” In other words, is sentiment analysis really, as Jockers says, “good enough”?
The short answer is: we can’t tell.
Sentiment analysis experts deal with this problem by assembling corpora of human-annotated documents, such as manually-evaluated tweets or movie reviews (which are “annotated” by how many stars the viewer gave the movie). They can use this data both to train and to test their algorithms, measuring how frequently the machine provides the same response as an “average” human.
For novels, we have no such corpus with which to test a sentiment analyzer, and so our evaluations are pure guesswork: we hope that phrases like “not good” and “like a potato” don’t happen too often; we hope that sarcasm and satire are infrequent enough; we hope that errors in sentence-splitting won’t affect our results; but ultimately we cannot confirm it either way.
This is not to say that the project is doomed: we could approach this problem using the same strategies mentioned above. For example, we could ask scholars to mark the emotional valence of many novels sentence by sentence (or paragraph by paragraph, perhaps) using some crowdsourcing tool, and use this to create benchmarks showing us exactly how people evaluate emotional trajectories, on average.[2] Then, as different packages emerge that purport to analyze the emotional valence of novels, we could actually compare them with a large corpus of human-annotated texts.
While Jockers agrees that comparing Syuzhet’s outputs with human-annotated texts “would be a great test,” it’s more than merely useful: it’s absolutely necessary. Without such benchmarks, we have no way to assess the validity of Syuzhet’s sentiment analysis; we can only guess based on the way it handles sample sentences.[3]
All in all, Syuzhet’s lack of benchmarks and inaccurate foundation shapes are cause for concern. It has a long way to go before we can make reliable claims about the number of archetypal plot shapes novels share.
[1] His 2010 paper “Sentiment Analysis and Subjectivity” includes a discussion of the more complicated analyses beyond basic word-counting that are required for state-of-the-art sentiment analysis.
[2] It’s also possible that we’d discover some novels where the individual differences between readers make it impossible to determine a consensus; perhaps there are novels that have no “emotional trajectory” at all?
[3] As we’ve already seen, this leaves much to be desired.
I’ve been watching the developments with Matthew Jockers’s Syuzhet package and blog posts with interest over the last few months. I’m always excited to try new tools that I can bring into both the classroom and my own research. For those of you who are just now hearing about it, Syuzhet is a package for extracting and plotting the “emotional trajectory” of a novel.
The Syuzhet algorithm works as follows: First, you take the novel and split it up into sentences. Then, you use sentiment analysis to assign a positive or negative number to each sentence indicating how positive the sentence is. For example, “I’m happy” and “I like this” would have positive numbers, while “This is terrible” and “Everything is awful” would get negative numbers. Finally, you smooth out these numbers to get what Jockers calls the “foundation shape” of the novel, a smooth graph of how emotion rises and falls over the course of the novel’s plot.
This is an interesting idea, and I installed the package to try it out, but I’ve encountered several substantial problems along the way that challenge Jockers’s conclusion that he has discovered “six, or possibly seven, archetypal plot shapes” common to novels. I communicated privately with him about some of these issues last month, and I hope these problems will be addressed in the next version of the package. Until then, users should be aware that the package does not work as advertised.
I’ll proceed step-by-step through the process of using the package, explaining the problems at each step.
The first step of the algorithm is to split the text into sentences using Syuzhet’s “get_sentences” function. I tried running this on Charles Dickens’s Bleak House, and immediately ran into trouble: in many places, especially around dialogue, Syuzhet incorrectly interpreted multiple sentences as being just one sentence. This seemed to be particularly common around quotation marks. For example, here’s one “sentence” from the middle of Chapter III, according to Syuzhet:[1]
Mrs. Rachael, I needn’t inform you who were acquainted with the late Miss Barbary’s affairs, that her means die with her and that this young lady, now her aunt is dead–”
“My aunt, sir!”
“It is really of no use carrying on a deception when no object is to be gained by it,” said Mr. Kenge smoothly, “Aunt in fact, though not in law.
As you can imagine, these grouping errors are likely to cause problems for works with extensive dialogue (such as most novels and short stories).[2]
The second step is to compute the emotional valence of each sentence, a problem known as sentiment analysis. The Syuzhet package provides four options for sentiment analysis: “Bing”, “AFINN”, “NRC”, and “Stanford”; “Bing” is the default, and is what Jockers recommends in his documentation.
“Bing,” “AFINN,” and “NRC” are all simple lexicons: each is a list of words with a precomputed positive or negative “score” for each word, and Syuzhet computes the valence of a sentence by simply adding together the scores of every word in it.
This approach has a number of drawbacks:
To demonstrate some of these problems, I composed the following simple paragraph:
I haven’t been sad in a long time.
I am extremely happy today.
It’s a good day.
But suddenly I’m only a little bit happy.
Then I’m not happy at all.
In fact, I am now the least happy person on the planet.
There is no happiness left in me.
Wait, it’s returned!
I don’t feel so bad after all!
According to common sense, we’d expect the sentiment assigned to these sentences to start off fairly high, then decline rapidly from lines 4 to 7, and finally return to neutral (or slightly positive) at the end.
Using the Syuzhet package, we get the following sentiment trajectory:

The emotional trajectory does pretty much exactly the opposite of what we expected. It starts negative, because “I haven’t been sad in a long time” contains only one word with a recognized value, which is “sad.” Then it rises to be at the same level of positivity for the next few lines, because “I am extremely happy today.” and “There is no happiness left in me” are equally positive. At the end, as the narrative turns hopeful again, Syuzhet’s trajectory drops back to negative because it detected the word “bad” in the sentence. [4]
This example showcases a number of the weaknesses of this sentiment analysis strategy on very straightforward text; I expect that these problems will be far worse for novels that contain emotion implied though metaphors or imagery patterns, or use satire and sarcasm (e.g. most works by Jane Austen, Jonathan Swift, Mark Twain, or Oscar Wilde), irony, or an unreliable narrator (e.g. much of postmodern literature).
Essentially, the Syuzhet package creates graphs of word frequency grouped by theme (positive and negative) throughout a text more than it does graphs of emotional valence in a text.
The final step of Syuzhet is to turn the emotional trajectory into a Foundation Shape–a simplified graph of the story’s emotional valence that (hopefully) echoes the shape of the plot. But once again, I found some problems. Syuzhet produces the Foundation Shape by putting the emotional trajectory through an ideal low-pass filter, which is designed to eliminate the noise of the trajectory and smooth out its extremes. Ideal low-pass filters work by approximating the function with a fixed number of sinusoidal waves; the smaller the number of sinusoids, the smoother the resulting graph will be.
However, ideal low-pass filters often introduce extra lobes or humps in parts of the graph that aren’t well-approximated by sinusoids. These extra lobes are called ringing artifacts, and will be larger when the number of sinusoids is lower.
Here’s a simple example:


The graph on the left is the original signal, and the graph on the right demonstrates the ringing artifacts caused by a low-pass filter (specifically, by zeroing all but the first five terms of the Fourier transform). The original signal just has one lobe in the middle, but the low-pass filter introduces extra lobes on either side.
By default, Syuzhet uses an even lower cutoff than the example above (keeping only three Fourier terms). Consequently, we should expect to find inaccurate lobes in the resulting foundation shapes. The Portrait of the Artist foundation shape that Jockers presented in his post “Revealing Sentiment and Plot Arcs with the Syuzhet Package” already shows this: [5]


The full trajectory opens with a largely flat stretch and a strong negative spike around x=1100 that then rises back to be neutral by about x=1500. The foundation shape, on the other hand, opens with a rise, and in fact peaks in positivity right around where the original signal peaks in negativity. In other words, the foundation shape for the first part of the book is not merely inaccurate, but in fact exactly opposite the actual shape of the original graph.
This is a pretty serious problem, and it means that until Syuzhet provides filters that don’t cause ringing artifacts, it is likely that most foundation shapes will be inaccurate representations of the stories’ true plot trajectories. Since the foundation shape may in places be the opposite of the emotional trajectory, two foundation shapes may look identical despite having opposing emotional valences. Jockers’s claim that he has derived “the six/seven plot archetypes” of literature from a sample of “41,383 novels” may be due more to ringing artifacts than to an actual similarity between the emotional structures of the analyzed novels.
While Syuzhet is a very interesting idea, its implementation suffers from a number of problems, including an unreliable sentence splitter, a sentiment analysis engine incapable of evaluating many sentences, and a foundation shape algorithm that fundamentally distorts the original data. Some of these problems may be fixable–there are certainly smoothing filters that don’t suffer from ringing artifacts[6]–and while I don’t know what the current state of the art in sentence detection is, I imagine algorithms exist that understand quotation marks. The failures of sentiment analysis, though, suggest that Syuzhet’s goals may not be realizable with existing tools. Until the foundation shapes and the problems with the implementation of sentiment analysis are addressed, the Syuzhet package cannot accomplish what it claims to do. I’m looking forward to seeing how these problems are addressed in future versions of the package.
Special Thanks:
I’d like to thank the following people who have consulted with me on sentiment analysis and signal processing and read versions of this blog post.
Daniel Lepage, Senior Software Engineer, Maternity Neighborhood
Rafael Frongillo, Postdoctoral Fellow, Center for Research on Computation and Society, Harvard University
Brian Gawalt, Senior Data Scientist, Elance-oDesk
Sarah Gontarek
[1] The excerpt doesn’t include quotation marks at the beginning and end because both the opening and closing sentences are part of larger passages of dialogue.
[2] This problem was not visible with the sample dataset of Portrait of the Artist, because the Project Gutenburg text uses dashes instead of quotation marks.
[3] This example also shows another problem: longer sentences may be given greater positivity or negativity than their contents warrant, merely because they have greater number of positive or negative words. For instance, “I am extremely happy!” would have a lower positivity ranking than “Well, I’m not really happy; today, I spilled my delicious, glorious coffee on my favorite shirt and it will never be clean again.”
[4] The Stanford algorithm is much more robust: it has more granularity in its categories of emotion and does consider negation. However, it also fails on the sample paragraph above, and it produced multiple “Not a Number” values when we ran it on Bleak House, rendering it unusable.
[5] Other scholars have also been noticing similar problems, as Jonathan Goodwin’s results demonstrate: (https://twitter.com/joncgoodwin/status/563734388484354048/photo/1).
[6] For example, Gaussian filters do not introduce ringing artifacts, though they have their own limitations (http://homepages.inf.ed.ac.uk/rbf/HIPR2/freqfilt.htm).
I’m happy to report that SUNY New Paltz has funded an interdisciplinary digital scholarship center to be housed in the Sojourner Truth Library! My colleague Melissa Rock (Department of Geography) and I submitted a grant proposal for internal funds, and the President and Provost agreed to fully fund its initial start-up. We’re very excited that the administration has decided to make digital scholarship such a high priority!
We’re still tossing around name ideas–the current leader is Digital Arts, Social Sciences, and Humanities Lab (DASSH Lab, for short)–and we won’t have access to our new space for a few months yet, but we’re working on setting up a temporary home as we gear up for workshops, training sessions for classes, and a speaker series.
Here’s the information about the center:
Faculty members in departments throughout the university, including Geography, English, Education, Anthropology, Computer Science, Biology, and Graphic Design, have expressed great interest in integrating digital technologies into their own research and classroom curricula. However, they lack the expertise, equipment, and access to space necessary to use these technologies effectively; most specialized computer labs are reserved for professors and students in that department, and most other computer labs, in addition to lacking specialized software, are consistently booked with classes. This center will provide the training, equipment, and software, and workshops necessary for faculty from throughout the campus to support teaching and learning with digital technology by creating digital video essays, podcasts, websites, digital archives and editions, and visualizations. This center is vital to ensure that SUNY New Paltz professors are using cutting-edge techniques in their research and pedagogy.
Stay tuned for more information!
