[Update: Matthew Jockers posted a response to this critique yesterday. Rather than contribute to what he calls a “blogging frenzy,” and in the absence of a comments field on his blog, I will make a few points here:
1) It is clear that the Syuzhet package needs more peer review and rigorous testing — designed to confirm or refute hypotheses — before it will be possible to make valid claims about archetypal plot structures. I have attempted to model that testing and review here.
2) Matt seems to misunderstand my critique. I am not arguing about whether or not Portrait of the Artist represents a “man in a hole” plot shape; I’m pointing out that any Syuzhet plot shape can easily be the result of low-pass filter artifacts instead of a reflection of the computed sentiment (itself hard to analyze at the single word or sentence level), and that they therefore cannot yet be said to reliably reflect the emotional trajectories of novels.]
[This is a continuation of an ongoing dialogue about the Syuzhet package and literary text-mining. If you want to know the full history, check out Eileen Clancy’s Storify on the subject.]
[Update: The code that generates the graphs for this blog post is now available at https://github.com/jswafford/syuzhet-samples.]
A few weeks ago, Matthew Jockers published Syuzhet, an interesting package for the programming language R that uses sentiment analysis, together with a low-pass filter, to uncover one of “six, or possibly seven, archetypal plot shapes” (also known as foundation shapes) in any novel. Earlier this week, I posted a response, documenting some potential issues with the package, including problems with the sentence splitter, inaccuracies in the sentiment analysis algorithms, and ringing artifacts in the foundation shapes. A few days ago, Jockers responded; his newest blog post claims that while some of these problems do exist, they are limited to “one sentence here or one sentence there” and that in aggregate, the sentiment analysis succeeds. Jockers cites the apparent similarities in the emotional trajectories and foundation shapes produced with several different sentiment analysis algorithms on the same text as proof that Syuzhet is “good enough” that we can draw meaningful conclusions based on its foundation shapes.
This blog post investigates this claim, and draws two conclusions:
- We can’t learn much from foundation shapes, because they don’t always reflect the emotional valence of novels; in extreme cases, Syuzhet’s foundation shapes can be virtually unrelated to the estimated sentiments of their novels.
- We cannot truly evaluate whether the sentiment analysis methods are “good enough” without benchmarks to define success.
Foundation Shapes
In his recent blog post, Jockers presents the emotional valences for Portrait of the Artist generated by Syuzhet’s four different sentiment analysis algorithms (left-hand graph), and the resulting foundation shapes (right-hand graph):
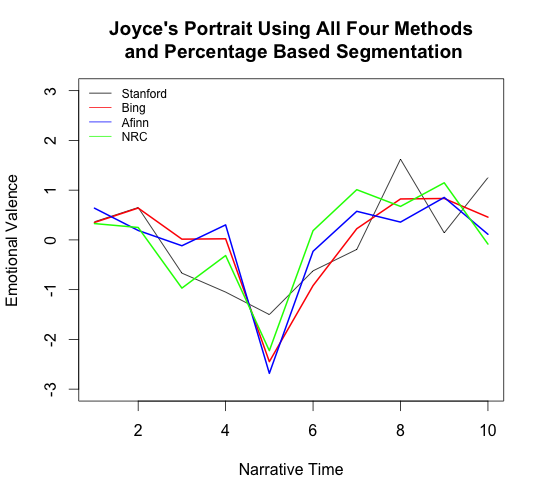
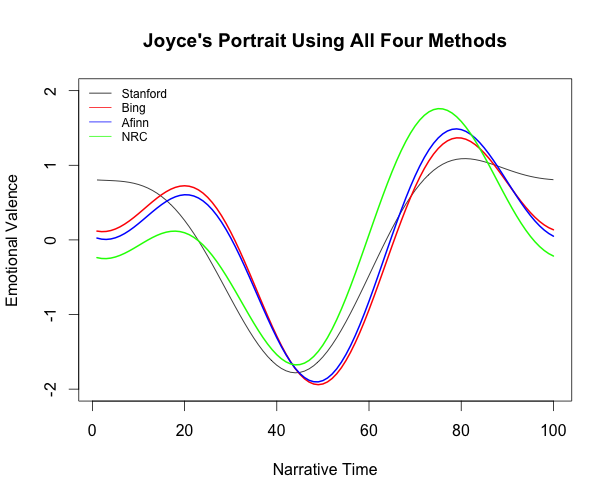
Although there are noticeable similarities between the four emotional valences in the graph on the left, they also have some significant differences, such as at x=8 where the Stanford line reaches its maximum while the Afinn and NRC lines drop downwards. And yet, these differences disappear in the foundation shapes on the right: all four curves reach their maximum around the 80% mark.
Jockers believes that these similar foundation shapes indicate that Syuzhet works, and that, despite the unreliability of the sentiment analysis, Syuzhet can still find the “latent emotional trajectory that represents the general sense of the novel’s plot.” I worried, though, that some of these similarities may be more due to ringing artifacts (which I discussed in my last post) than due to actual agreement between the different sentiment analysis methods.
Fortunately, there’s an easy way to test this: we can manually change the emotional valence for Portrait of the Artist and see if the foundation shape changes accordingly. For example, we can take the sentiment estimated by the bing method and simply set the valence for the final third of the novel to 0 (neutral sentiment): this is the equivalent of keeping the first two thirds of Portrait of the Artist the same, but changing the final third of the novel to consist of exclusively emotionless words. We would expect that the foundation shape would flatten out to 0 during the final third to reflect this change. Here’s what happens:
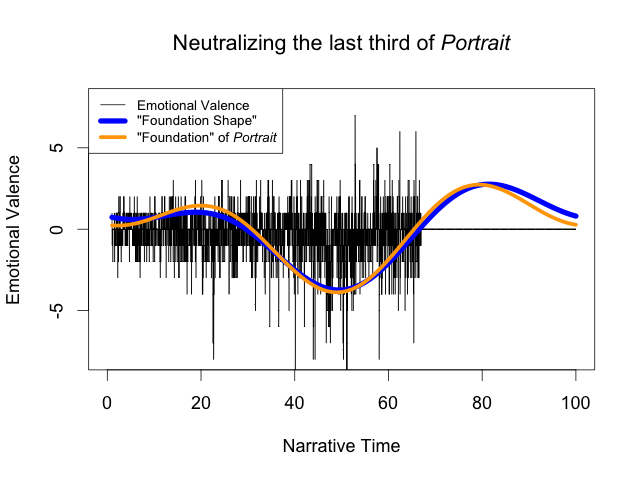
Surprisingly, the foundation shape is nearly identical: this suggests that the rise in the final third of the foundation shape is indeed a ringing artifact and not a result of an increase in positive emotion in the text.
In fact, we can take this even further: the foundation shape remains the same even if we make all but the middle twenty sentences of Portrait of the Artist neutral, leaving less than 0.5% of the novel unchanged:
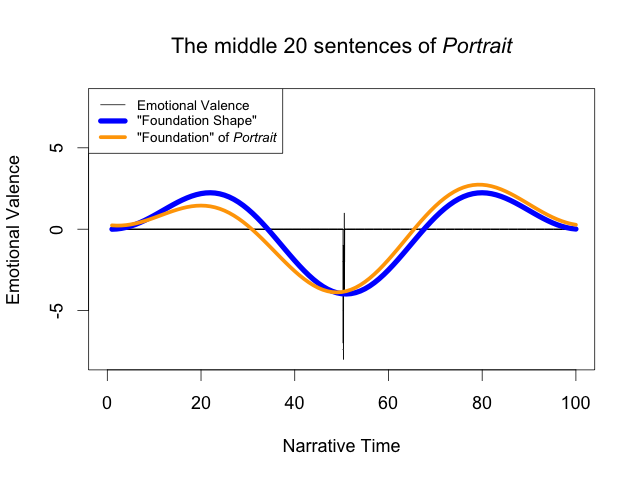
These observations cast Jockers’s comparison of the sentiment analyzers in a new light. Their similar foundation shapes do not validate Syuzhet’s sentiment analysis algorithm; they merely demonstrate that Syuzhet’s foundation shapes can make dissimilar curves similar.
This is not to say that the values at the ends never matter; as another experiment, I artificially raised the emotional valence of the opening and closing two-hundred sentences of Portrait of the Artist (about 8% of the novel), leaving the rest unchanged. This is the equivalent of changing the text of Portrait of the Artist so the opening and closing are extremely happy:
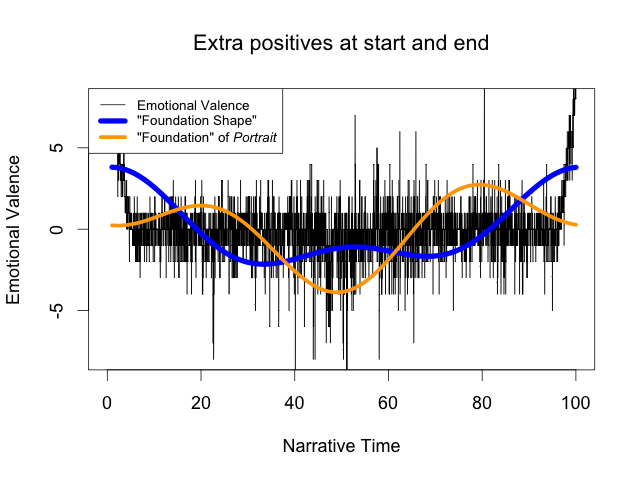
Interestingly, the new foundation shape (blue) now shows the midpoint of the novel as less negative than the area around it, even though it is still the most negative portion of the story (since we only changed the very beginning and end). This is a classic ringing artifact: the foundation shape can’t reflect the emotional heights at both ends of the story without altering the middle because the correct shape cannot be approximated by low-frequency sinusoids.
Since we’ve now seen several foundation shapes that don’t reflect the emotional valences that generated them, it’s reasonable to wonder just how dissimilar two graphs could be while still maintaining the same foundation shape. I asked Daniel Lepage (a professional programmer with a degree in mathematics) how we might find such graphs. He pointed out that Syuzhet computes foundation shapes by discarding all but the lowest terms of the Fourier transform. This means that stories where much of the emotional valence is determined by higher terms can have wildly different valences, yet still share a foundation shape. To test this, he created multiple signals—graphs of the emotional valences of hypothetical texts—that share the foundation shape of Portrait of the Artist (according to Syuzhet):
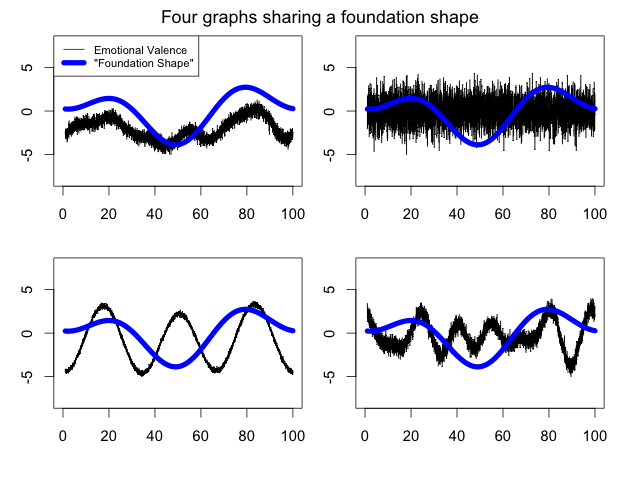
These sample signals clearly have very little in common with each other or with Portrait of the Artist, and yet they all produce completely identical foundation shapes, so a foundation shape may be entirely unlike the emotional trajectory of its novel.
The fourth example signal is particularly interesting: practically all of the variation is determined by the higher Fourier terms. This means that by making nearly-invisible low-frequency changes to the original valence, we can completely alter its foundation shape:
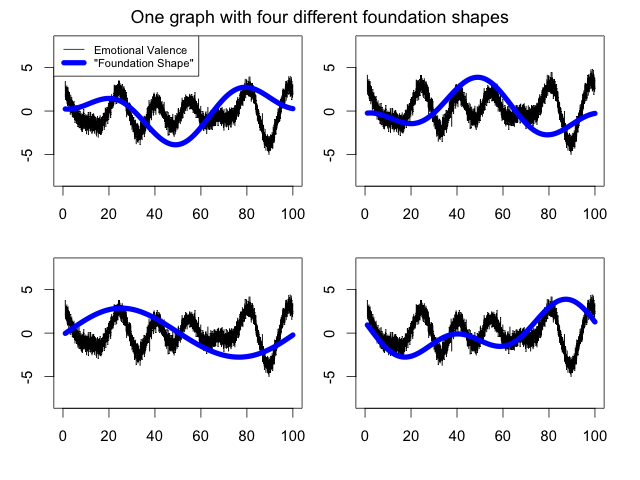
Obviously, this is a worst-case scenario: it is unlikely that a real book would perform quite so badly. Nonetheless, this proves that we cannot assume that Syuzhet’s foundation shapes reliably reflect the emotional trajectories of their novels.
Sentiment Analysis
Of course, the quality of the foundation shapes is a moot point unless we trust the underlying sentiment analysis. Jockers and I essentially agree on the worth of sentiment analysis as applied to novels: in his words, “Frankly, I don’t think any of the current sentiment detection methods are especially reliable.” All approaches—from the lexicon-based approaches to the more advanced Stanford parser—have difficulty with anything that doesn’t sound like a tweet or product review, which is not surprising. He and I have both shown a number of examples in which sentiment analysis fails to produce the emotional valence that a human would assign—such as “Well, it’s like a potato”—which suggests that modern sentiment analysis may not be up to the task of handling the emotional complexities of novels.
Although the Stanford parser does boast 80-85% accuracy, it was trained and tested on movie reviews, which do not generally have the same degrees of ambiguity and nuance as novels. The other three analysis methods Syuzhet provides are all based on word-counting; a cursory examination of modern sentiment analysis literature indicates that this hasn’t been the state of the art for quite some time. Even Bing Liu, creator of the Bing lexicon (Syuzhet’s default lexicon), states on his website that “although necessary, having an opinion lexicon is far from sufficient for accurate sentiment analysis.”[1]
Ultimately, however, this debate is skirting the real issue, which Lisa Rhody raised in a comment on my last blog post. She asked how “sentence-level errors in detecting sentiment present problems in the aggregate” and wondered “how these errors might build on themselves to continue to cause concern at scale.” In other words, is sentiment analysis really, as Jockers says, “good enough”?
The short answer is: we can’t tell.
Sentiment analysis experts deal with this problem by assembling corpora of human-annotated documents, such as manually-evaluated tweets or movie reviews (which are “annotated” by how many stars the viewer gave the movie). They can use this data both to train and to test their algorithms, measuring how frequently the machine provides the same response as an “average” human.
For novels, we have no such corpus with which to test a sentiment analyzer, and so our evaluations are pure guesswork: we hope that phrases like “not good” and “like a potato” don’t happen too often; we hope that sarcasm and satire are infrequent enough; we hope that errors in sentence-splitting won’t affect our results; but ultimately we cannot confirm it either way.
This is not to say that the project is doomed: we could approach this problem using the same strategies mentioned above. For example, we could ask scholars to mark the emotional valence of many novels sentence by sentence (or paragraph by paragraph, perhaps) using some crowdsourcing tool, and use this to create benchmarks showing us exactly how people evaluate emotional trajectories, on average.[2] Then, as different packages emerge that purport to analyze the emotional valence of novels, we could actually compare them with a large corpus of human-annotated texts.
While Jockers agrees that comparing Syuzhet’s outputs with human-annotated texts “would be a great test,” it’s more than merely useful: it’s absolutely necessary. Without such benchmarks, we have no way to assess the validity of Syuzhet’s sentiment analysis; we can only guess based on the way it handles sample sentences.[3]
All in all, Syuzhet’s lack of benchmarks and inaccurate foundation shapes are cause for concern. It has a long way to go before we can make reliable claims about the number of archetypal plot shapes novels share.
[1] His 2010 paper “Sentiment Analysis and Subjectivity” includes a discussion of the more complicated analyses beyond basic word-counting that are required for state-of-the-art sentiment analysis.
[2] It’s also possible that we’d discover some novels where the individual differences between readers make it impossible to determine a consensus; perhaps there are novels that have no “emotional trajectory” at all?
[3] As we’ve already seen, this leaves much to be desired.

Validating sentiment analysis on novels is a great idea. I like out-of-sample predictive accuracy whenever I can get it.
But in some ways it wouldn’t get at the real question here. It would show us that a sentiment model can correctly reproduce contemporary readers’ answers to a particular survey question with 80-85% accuracy. But I actually have no doubt that a bag-of-words model can do that.
The question is, what does our survey question (however we phrase it, about “sentiment” or “tone” or what have you) tell us about the history of plot? That’s going to be harder to test.
I think actually the validation we need here is historical. If some of Matt’s foundation shapes turn out to be more common in particular periods or genres, I’m going to be pretty interested. If we can plausibly explain why they’re distributed differently across genre/time, I’m going to be very interested. Then I might start wondering whether we can get better results by tuning the Fourier transform, or changing the model of sentiment. But I don’t feel that I know in advance whether the approach will work; it’s an experiment.
LikeLike
Hi Ted,
Thanks for your comment! I agree that it would be fascinating if we could find common patterns across genres and periods to learn about the history of plot. That being said, I think it’s highly unlikely given the amount of data being thrown out to create the foundation shapes. Also, given that foundation shapes do not always reflect the plots of their novels, any similarities in foundation shapes over time would not necessarily tell us anything about plots (or sentiment, or tone) over time.
I certainly hope you’re right that a bag-of-words model can predict the sentiment of sentences in a novel with such accuracy; however, given that sentiment analysis experts are spending lots of time and money researching how to make their algorithms more accurate (Stanford’s is only 80% accurate on simple movie reviews), I’d be surprised to discover it’s as much of a solved problem as you seem to suggest.
Also, a side note: when I suggested crowdsourcing, I was envisioning crowdsourcing done by and for scholars/experts in the field, rather than the typical Amazon Mechanical Turk model (for reasons similar to those you mentioned in your “How Not to Do Things With Words” blog post, which I just taught in my DH class last week). Prism (http://prism.scholarslab.org/) might actually work really well for this (thanks to Bethany Nowviskie for pointing this out to me).
Thanks for your input!
–Annie
LikeLike
[…] in her ongoing critique of Syuzhet, the R package that I released in early February. In her recent blog post, an interesting approach for testing the get_transformed_values function is […]
LikeLike
[…] March 7, Annie Swafford posted an interesting critique of the transformation method implemented in Syuzhet. Her basic argument is that setting the […]
LikeLike
[…] shapes) in any novel.[1] Matt[2] wrote a new blog post defending his tool and claiming that my testing framework, which demonstrated that foundation shapes don’t “always reflect the emotional valence of […]
LikeLike
[…] using a Fourier transform and low-pass filter, is appropriate. Annie Swafford has produced several compelling arguments that this strategy doesn’t work. And Ted Underwood has responded with what is […]
LikeLike
[…] Annie Swafford, “Continuing the Syuzhet Discussion,” Anglophile in Academia: Annie Swaf… […]
LikeLike