There’s been a flurry of activity on the continuing question of Matt Jockers’ Syuzhet package that purports to use sentiment analysis and a low-pass filter to find the “six, or possibly seven, archetypal plot shapes” (also known as foundation shapes) in any novel.[1] Matt[2] wrote a new blog post defending his tool and claiming that my testing framework, which demonstrated that foundation shapes don’t “always reflect the emotional valence of novels,” actually proved the success of his tool. This blog post will respond to that claim as well as to recent comments by Andrew Piper on questions of how we validate data in the Humanities.
First, though, let’s start with Matt’s most recent post. Matt claims that Syuzhet’s purpose is to “approximat[e] the fundamental highs and lows of emotional valence” in a novel. Unfortunately, by his own criteria, Syuzhet fails. This is not a matter of opinion and it is something we can test.
On Syuzhet
Matt used a method I’d suggested—changing the emotional valence of sections of a novel to 0 (neutral emotion)—to generate foundation shapes for variants on Portrait of the Artist. Although he cites these images as evidence of the success of Syuzhet, they actually prove just how broken Syuzhet is. For example, he “neutralizes” the sentiment for the final third of Portrait of the Artist, observes that the foundation shape is essentially unchanged, points out the original novel’s emotional valence was essentially neutral, and claims that this is proof that the foundation shapes work correctly: “So all we have really achieved in this test is to replace a section of relatively neutral valence with another segment of totally neutral valence.” He’s right that in both cases, the final third of the signal has mostly neutral valence: however, he overlooks the fact that the foundation shape doesn’t.
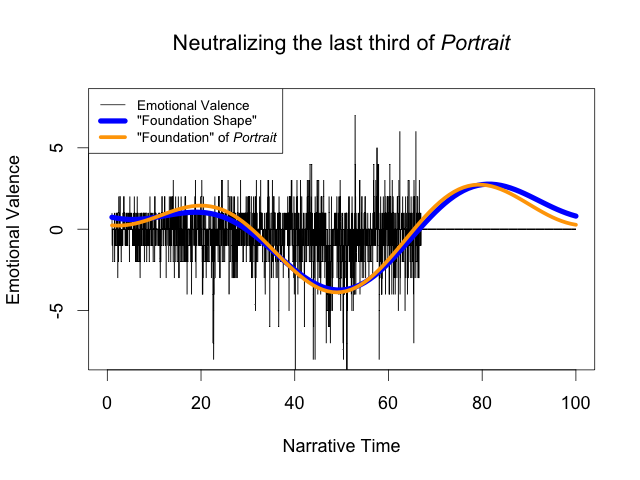 Instead of being a flat line, it rises substantially, which should only occur for positive sentiment. If Syuzhet is designed to “approximat[e] the fundamental highs and lows of emotional valence,” then it fails dramatically, because the “high” in the altered Portrait of the Artist should not appear in a section of neutral sentiment.
Instead of being a flat line, it rises substantially, which should only occur for positive sentiment. If Syuzhet is designed to “approximat[e] the fundamental highs and lows of emotional valence,” then it fails dramatically, because the “high” in the altered Portrait of the Artist should not appear in a section of neutral sentiment.
Matt again misses the point of my testing algorithm when he artificially raises and lowers the emotion at the end of the novel: while he correctly notes that raising or lowering the emotion of the end of the novel causes the foundation shape at the end to also raise or lower, he fails to notice that this also alters the earlier parts of the foundation shape to make it incorrect. In fact, simply changing the final third of the story causes the relative highs and lows of the first two-thirds to be completely inverted:
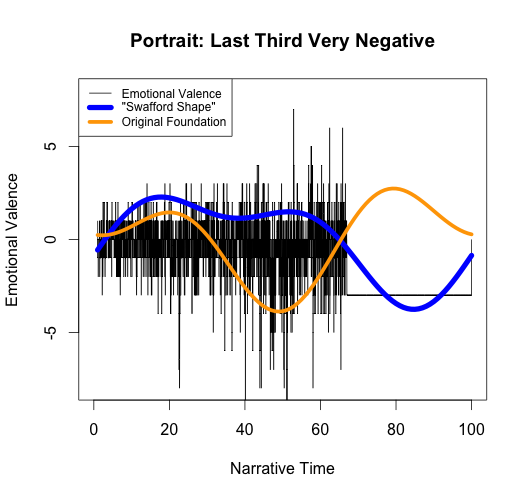
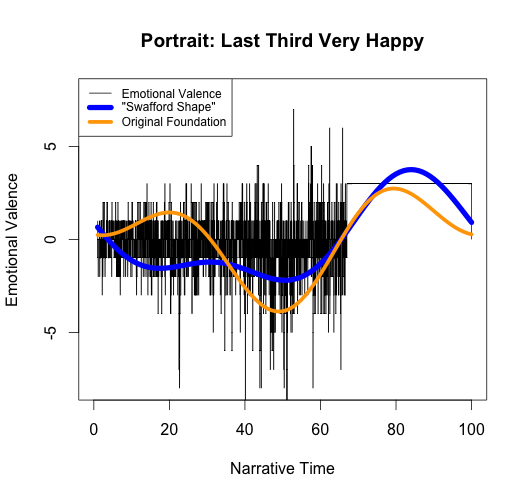
If the foundation shape truly reflected the emotional valence of the novel, it wouldn’t invert where the text remains the same. Yet again, it fails to “approximate the fundamental highs and lows of emotional valence.”
Matt then claims that “If we remove the most negative section of the novel, then we should see the nadir of the simple shape shift to the next most negative section.” This is true, but it also highlights the failure of the algorithm: as we see in the “Neutralized Middle” graph, the second-lowest point of the raw sentiment (around x=20) was the second-highest point of the original foundation shape (shown here in orange):
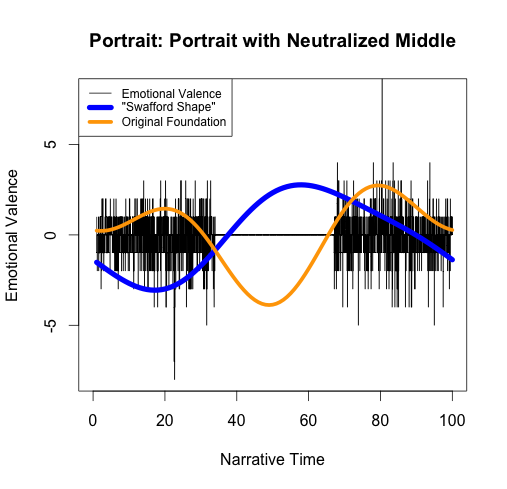
Obviously this is not estimating the “highs and lows” of the story – it’s finding one low and ignoring the rest. Of course, if we define success for Syuzhet as “it identifies the single highest or lowest point in a story,” then we could call the above figure a success as Matt claims, but if this is the goal then 1. It could have been done much more simply by just choosing the lowest point of the original sentiment, and 2. It’s a bad proxy for Vonnegut’s notion of “plot shape” because it can’t distinguish between multiple shapes that have similar lowest points.
The latter point is particularly problematic. The “Man in a Hole” plot shape is not the only one with a nadir in the middle: Vonnegut’s “Boy meets Girl” plot shape also has its greatest moment of negativity in the middle of the story.
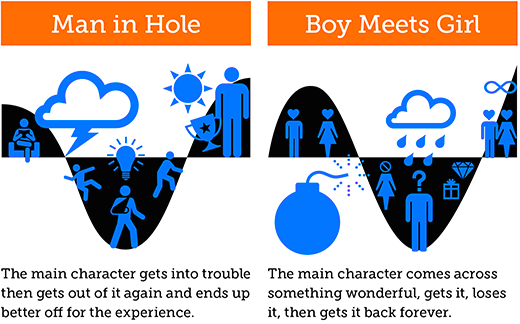
As a result, if we only at the lowest point only and consider rises or falls on either side irrelevant, as Matt does, then we can’t tell the differences between them. It’s also interesting to note that the foundation shape for Portrait of the Artist rises, falls, rises again, and falls again, which makes it much closer to a “Boy meets Girl” shape than the “Man in a Hole” that Matt continuously insists it is (though neither shape should have that final fall at the end). In short, the foundation shapes don’t just “miss some of the subtitles [sic]” in the data; they flat out distort it and introduce errors that in places make the foundation shape the opposite of the emotional trajectory.
Matt also objects to my using Syuzhet’s default value of 3 as the cutoff for the low pass filter for my graphs, stating that, as it is a “user tunable parameter,” it can be raised to reduce the ringing artifacts. I generated the examples with the default value because it is the number he used in his clustering, from which he concluded that there are only 6 or 7 plot shapes. Raising that number isn’t really a solution for two reasons: 1. It wouldn’t eliminate the ringing (ringing artifacts happen with any low-pass filter, though they’ll be smaller with higher cutoffs); and 2. It would require redoing all the clustering that led to these “archetypal” shapes, as the number and type of common plot shapes will likely be dramatically different with more terms.
Overall, there is no point in “seek[ing] to identify an ‘ideal’ number of components for the low pass filter,” because the low-pass filter is a poor choice for this resampling application: Gaussian blurring and a simple window average would be more successful because they would simplify the data without distorting it. In an earlier blog post, Matt justifies the low-pass filter instead of a simple window average (which he has already implemented as get_percentage_values) by claiming “You cannot compare [the results of get_percentage_values] mathematically because the amount of text inside each percentage segment will be quite different if the novels are of different lengths, and that would not be a fair comparison.” This suggests that he misunderstands the mathematics behind the low-pass filter he has implemented, because this statement is just as true of low-pass filtering as it is of get_percentage_values: each value in the result is a weighted average of the original values, and more text is averaged per data point in a longer novel than in a shorter one. If this really were an unfair comparison, then the entire Syuzhet project would be hopeless.
On Validation in the Humanities
The errors with Syuzhet and this whole debate about whether or not it works relate to a larger question about validating a tool in the Humanities, which Andrew Piper touched on in his recent blog post: “Validation is not a process that humanists are familiar with or trained in. We don’t validate a procedure; we just read until we think we have enough evidence to convince someone of something.” Unfortunately, “read[ing] until we think we have enough evidence” doesn’t work with programming and science: programmers and scientists must actually design tests to make sure that the tools we build work as advertised. Building tools for distant reading therefore involves at least two types of validation: the first type requires making sure the tool works as expected, and the second type, possible only once the first type of validation works, requires analyzing the results of the tool to come up with new theories about history, literary history, or plot, or whatever the primary subject matter is for a given corpora. My blog posts have focused on the first type of validation: I have provided some sample tests where Syuzhet clearly fails, which means that we need to go back to fix the tool before we can take its output seriously and analyze it.
Fortunately, coming up with a way to perform the first type of validation for a Humanities tool is not as dire a problem as Andrew Piper suggested when he wrote “We can’t import the standard model of validation from computer science because we start from the fundamental premise that our objects of study are inherently unstable and dissensual.” As it turns out, the Humanities are not unique in studying the liminal or the multifaceted: many subfields of computer science struggle with “unstable” data all the time, from image processing to machine learning. True sentiment analysis scholars work on this problem: they acknowledge that words are polysemous, that language is nuanced and ambiguous, and that everyone reads texts differently. That’s why they use human-annotated corpora of texts, from which they can estimate how an “average” reader evaluates documents, to measure how well their algorithms approximate that “average” reader. We can actually learn a lot about addressing this problem by collaborating with our colleagues from outside the Humanities.
This brings me to my final point: Digital Humanities is best when we collaborate. As Humanists, we’ve been very well trained in our particular field (or fields, if we double-majored once upon a time), but we often haven’t been trained in things like statistics, sentiment analysis, or signal processing. We’re used to researching a wide variety of subjects, and that can take us pretty far, but we’re unlikely to fully understand all the nuances of the fields we try to learn on our own, especially if they usually require a PhD in physics or math. A quick conversation with a colleague in a different field goes a long way towards finding exciting solutions to confounding problems, but it’s not going to be enough to fully explain things like ringing artifacts or Fourier transforms. The only way to make sure that we’re not introducing problems we could never have anticipated with our limited knowledge is by assembling a team of experts. Before I posted my first response to Syuzhet, I sought input from people in a wide variety of fields—electrical engineers, software developers, mathematicians, and machine learning specialists—to make sure my critiques were valid, and I credited them in my post. Without collaborative teams comprised of scholars from a wide variety of fields, digital humanities scholarship will continue to be plagued by easily avoidable errors.
NOTES:
[1] While Ted Underwood has claimed that Syuzhet is entirely exploratory and no scholarly claims have been made, I will take Matt at his word and respond to the thesis he has posited in several blog posts and news articles.
[2] Matt Jockers informed me that he prefers to go by his first name, so I will happily oblige in this post.

Fascinating post. Thanks for this whole debate; I think it’s been enormously productive for the whole field.
I thoroughly agree with your broader claims about “validation in the humanities” here. And I think that’s probably the most important part of this whole conversation.
In part, I guess the question of whether syuzhet is “exploratory” is a rhetorical question about Matt’s intentions, or about the way other people received his posts — and my reading of both those things could well be wrong.
It was only after a long conversation with Daniel Lepage that I realized what I was really trying to get at in that post — which is that, to me, questions about syuzhet’s low-pass option just aren’t the interesting part of this debate. The interesting question is, Was Vonnegut even right that these “shapes of stories” exist, as generalizations about different groups of novels?
They really might not even exist. It might not be possible to make meaningful generalizations about the relationship between plot and “sentiment.” Or these shapes of stories could exist in some very weak, tenuous sense that requires a lot of exploratory analysis to reveal. We might not yet know what sort of analysis.
When I say syuzhet is exploratory I don’t mean to make a claim about Matt’s intentions. I’m saying that it’s a package designed to attempt to reveal something that might not exist. And I would actually be just as interested in this conversation if it turns out that what you & Matt collectively, eventually prove is that Vonnegut is wrong, or that his alleged shapes of stories are (so to speak) very weak signals. That would be a huge thing to demonstrate.
I realize that, from your perspective, neither you nor Matt have demonstrated this yet — because syuzhet is unreliable. From my perspective, I don’t know. (For a lot of reasons, among them not having read Matt’s article.) But I’ll continue to follow the convo with interest, because the potential for literary discovery seems to me quite high even if syuzhet doesn’t quote-unquote “successfully” reveal the shapes Vonnegut alleged to exist.
LikeLike
I’m not an expert in gaussian filters and the like, but I do know a lot about validating subjective truths. Thus, now that the conversation has turned to that, I have a bit more to say. 😉 In particular, I read Andrew Piper’s blog post on the subject with interest, but absent the ability to comment over there (and absent my own blog), I’ll add my thoughts here; note that I’m generally referencing his post, however. My apologies for the length. I’m not known for my brevity.
[I’m address the argument somewhat out of order, and in two parts. Part 1 talks about subjectivity and the unknowable in computer science; part 2, validation of subjective and unknowable things]
Part 1: the humanities do not have the lock on subjectivity, nor the study of the unknowable.
Piper says: “We can’t import the standard model of validation from computer science because we start from the fundamental premise that our objects of study are inherently unstable and dissensual.”
This statement is what motivated me to post.
To start with a relatively small point: there is no standard model of CS validation; the subfields that comprise CS are simply too different.
That said: My research area is software engineering. Software is unique as compared to other engineering artifacts not least because it is constantly changing, in ways that we (humanity) don’t understand and largely cannot (yet?) model or predict. Engineering is the study of design and deployment under constraint, and those constraints are defined and enforced via the needs/desires of the various stakeholders in a system. “Dissensual” is actually very applicable.
The statement “the fundamental premise that our objects of study are inherently unstable and dissensual” is also the fundamental premise underlying my own research area. We still have (and are continuing to develop new) mechanisms to validate our claims, and many of those approaches could inform validation in DH.
But first, hopping up a level, it’s worth noting that computer science was born out of various proofs about the limits of what is computationally knowable. A short version of the implications: there are uncountably infinite problems we provably cannot solve, including virtually all that are studied in my corner of the world.
(If you’re lucky, your problem may be solvable, but computationally feasible only if something we all generally suspect is false but have yet been unable to prove so (P=NP) is actually true.)
Piper: “What is really at stake is not just validation per se, but how to validate something that is inherently subjective.”
I think computer science has a number of pointers to offer on how to do this, because we validate inherently subjective concerns all the time.
I strongly believe that program correctness falls into this category, but since that’s a debate on its own, I’ll start someplace simpler. Consider: program readability.
(“Raymond P. L. Buse and Westley R. Weimer. Learning a metric for code readability. IEEE Trans. Softw. Eng., 36(4):546–558, 2010.”)
Buse and Weimer seek to measure and predict the “readability” of program code, which they (correctly) frame as an intrinsically subjective, human judgement. The authors sought to develop a technique that could measure and evaluate program source code for its readability in a way that matches a general, subjective human judgement.
Consider: automatic documentation. Anything in tooling for programming support. The entire field of HCI. Much of graphics (where the goal is so often to make something “prettier”).
Indeed, one of my colleagues is currently teaching a PhD level course on empirically evaluating human-oriented research.
Part 2: validating in the face of subjectivity
Piper says: “How do we know when a curve is “wrong”? Readers will not universally agree on the sentiment of a sentence, let alone more global estimates of sentimental trajectories in a novel…. Before we extract something as subjectively constructed as a social network or a plot, we need to know the correlations between our algorithms and ourselves.”
Before you ask how often computers agree with humans, you need to know how often the humans agree with one another.* First, ask the question of a statistically significant sample of humans. Then, see how much they agree with one another (inter-annotator agreement). Use the aggregate answers as the ground truth for your models, and validate with respect to those answers and the inter-annotator agreement (you cannot expect an algorithm to agree with humans more than they agree with themselves). Use cross validation to ensure that your models are not overfit to the training data. Where possible, validate the model or algorithm against independent proxy measures. For example, if you’re validating a model that predicts code readability, you might take a sample of code that is known to be buggy as well as code that is known to be very good (because it was repaired later in its history or has been stable a long time, respectively; note that these signals do not rely strictly on the subjective human judgement readability is trying to estimate), and check that your metric can distinguish between them.
This latter approach is the type of validation Annie performed wherein she artificially manipulated the emotional valence of part of a body of work and checked the resulting foundation shapes. I found this particularly compelling.
*Assuming that human judgements on humanistic questions are not perfectly randomly distributed, which would (A) surprise me, (B) be interesting, and (C) suggest that the truth cannot be scientifically validated, and thus this argument is moot.
Piper says: “It’s not enough to say that sentiment analysis fails on this or that example or the smoothing effect no longer adequately captures the underlying data. One has to be able to show at what point the local errors of sentiment detection impact the global representation of a particular novel or when the discrepancy between the transformed curve and the data points it is meant to represent (goodness of fit) is no longer legitimate, when it passes from “ok” to “wrong,” and how one would go about justifying that threshold…”
I fervently disagree. This approach conflates knowledge of where exactly the line between correct and incorrect lies with knowledge of which side of the line something falls on. I can know that a program that crashes as soon as I launch it is incorrect without knowing what it should actually do instead. It would be *wonderful* to know the point at which the curves could be considered perfect, but requiring that to declare scientific victory sets the bar so high that actual advancement stagnates, since it precludes incremental progress.
If this *were* the standard for true progress, most computer scientists would have to close up shop since, as mentioned, most of our problems are provably impossible to solve perfectly. I would *definitely* be out of a job.
Piper says: “What I’m suggesting is that while validation has a role to play, we need a particularly humanistic form of it. As I’ve written elsewhere on conversional plots in novels, validation should serve as a form of discovery, not confirmation of previously held beliefs. Rather than start with some pre-made estimates of plot arcs, we should be asking what do these representations tell us about the underlying novels?… How can we build perspective into our exercises of validating algorithms?”
This is, incidentally, much of my concern about the syuzhet work (confirmation bias).
I agree that validation can inform discovery, and have anecdotes to support that belief. That said, validation still needs to be done in a scientifically principled way to establish the fundamentals of a technique before it can inform discovery, through the use of cross validation, agreement measures, measures of statistical significance, good underlying principles, and cross checking with alternative models with which the approach should agree.
I also think the last question (after the elision) is the type of question on which human-centered validation methods from other scientific fields could offer a lot of guidance to the DH community.
Piper says: “The debate between Jockers and Swafford is an excellent case in point where (in)validation isn’t possible yet. We have the novel data, but not the reader data. Right now DH is all texts, but not enough perspectives.”
Ah, and again, I disagree on the invalidating foundation shapes point. You don’t need reader perspective to know that a text constructed entirely of negative words shouldn’t have a foundation shape that matches man-in-hole.
However, I agree on the larger point, on a need for perspectives and human/reader data.
tl;dr: CS and the humanities could have a lot to teach one another about how to study subjective truths, if only we could talk to one another.
LikeLiked by 5 people
“tl;dr: CS and the humanities could have a lot to teach one another about how to study subjective truths, if only we could talk to one another.”
We can—I just joined the ranks of CMU, where you are. Let’s talk to one another!
LikeLiked by 1 person
Meh I’m bad at wp comments. Shoot me an email (on my web page). Let’s chat.
LikeLike
@scott: How funny! Where are you?
LikeLike
[…] transform and low-pass filter, is appropriate. Annie Swafford has produced several compelling arguments that this strategy doesn’t work. And Ted Underwood has responded with what is probably the […]
LikeLike
I got linked to this discussion thru Ben Schmidt’s recent blog post, so everybody’s probably moved on, but as an applied mathematician, the “take N low frequency components of the fourier spectrum” approach is not a good idea because it’s a non-causal filter, that is, information can flow from the future to the past. I think there’s nothing inherently wrong with doing some kind of low pass filter (and I would put the Gaussian blur that Annie Swafford mentioned in that category), but this particular one is in the category of “no, please don’t do that” for me.
LikeLike
[…] This can be a relatively blunt instrument – which justifiably leads humanists to treat it with suspicion – yet it also offers an opportunity to bring our own interpretative assumptions to a text […]
LikeLike
[…] Annie Swafford, “Why Syuzhet Doesn’t Work and How We Know,” Anglophile in Academia: A… […]
LikeLike