There’s been a flurry of activity on the continuing question of Matt Jockers’ Syuzhet package that purports to use sentiment analysis and a low-pass filter to find the “six, or possibly seven, archetypal plot shapes” (also known as foundation shapes) in any novel.[1] Matt[2] wrote a new blog post defending his tool and claiming that my testing framework, which demonstrated that foundation shapes don’t “always reflect the emotional valence of novels,” actually proved the success of his tool. This blog post will respond to that claim as well as to recent comments by Andrew Piper on questions of how we validate data in the Humanities.
First, though, let’s start with Matt’s most recent post. Matt claims that Syuzhet’s purpose is to “approximat[e] the fundamental highs and lows of emotional valence” in a novel. Unfortunately, by his own criteria, Syuzhet fails. This is not a matter of opinion and it is something we can test.
On Syuzhet
Matt used a method I’d suggested—changing the emotional valence of sections of a novel to 0 (neutral emotion)—to generate foundation shapes for variants on Portrait of the Artist. Although he cites these images as evidence of the success of Syuzhet, they actually prove just how broken Syuzhet is. For example, he “neutralizes” the sentiment for the final third of Portrait of the Artist, observes that the foundation shape is essentially unchanged, points out the original novel’s emotional valence was essentially neutral, and claims that this is proof that the foundation shapes work correctly: “So all we have really achieved in this test is to replace a section of relatively neutral valence with another segment of totally neutral valence.” He’s right that in both cases, the final third of the signal has mostly neutral valence: however, he overlooks the fact that the foundation shape doesn’t.
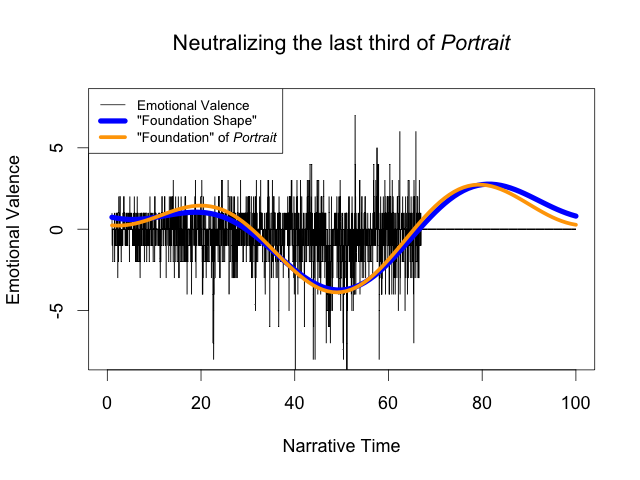 Instead of being a flat line, it rises substantially, which should only occur for positive sentiment. If Syuzhet is designed to “approximat[e] the fundamental highs and lows of emotional valence,” then it fails dramatically, because the “high” in the altered Portrait of the Artist should not appear in a section of neutral sentiment.
Instead of being a flat line, it rises substantially, which should only occur for positive sentiment. If Syuzhet is designed to “approximat[e] the fundamental highs and lows of emotional valence,” then it fails dramatically, because the “high” in the altered Portrait of the Artist should not appear in a section of neutral sentiment.
Matt again misses the point of my testing algorithm when he artificially raises and lowers the emotion at the end of the novel: while he correctly notes that raising or lowering the emotion of the end of the novel causes the foundation shape at the end to also raise or lower, he fails to notice that this also alters the earlier parts of the foundation shape to make it incorrect. In fact, simply changing the final third of the story causes the relative highs and lows of the first two-thirds to be completely inverted:
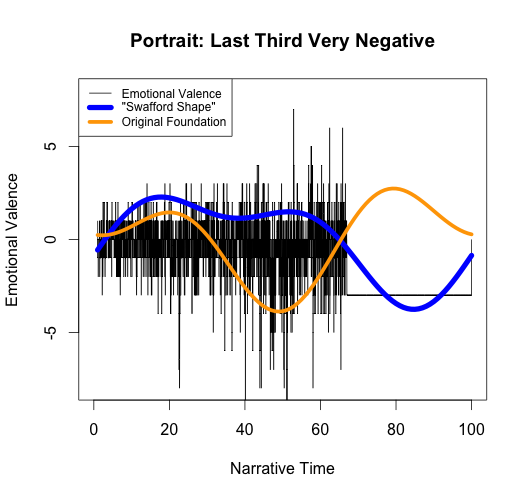
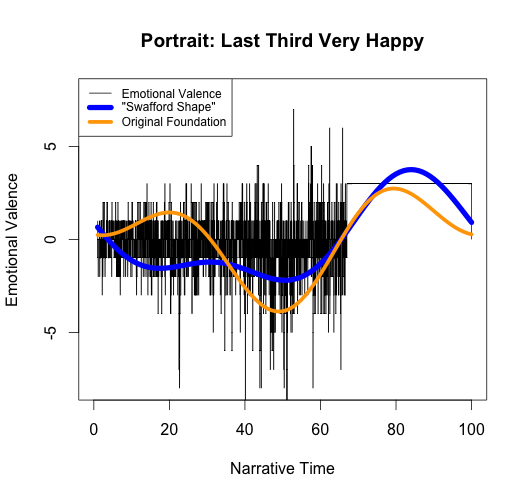
If the foundation shape truly reflected the emotional valence of the novel, it wouldn’t invert where the text remains the same. Yet again, it fails to “approximate the fundamental highs and lows of emotional valence.”
Matt then claims that “If we remove the most negative section of the novel, then we should see the nadir of the simple shape shift to the next most negative section.” This is true, but it also highlights the failure of the algorithm: as we see in the “Neutralized Middle” graph, the second-lowest point of the raw sentiment (around x=20) was the second-highest point of the original foundation shape (shown here in orange):
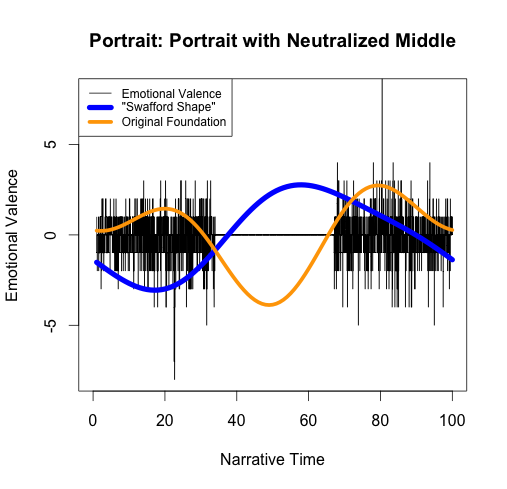
Obviously this is not estimating the “highs and lows” of the story – it’s finding one low and ignoring the rest. Of course, if we define success for Syuzhet as “it identifies the single highest or lowest point in a story,” then we could call the above figure a success as Matt claims, but if this is the goal then 1. It could have been done much more simply by just choosing the lowest point of the original sentiment, and 2. It’s a bad proxy for Vonnegut’s notion of “plot shape” because it can’t distinguish between multiple shapes that have similar lowest points.
The latter point is particularly problematic. The “Man in a Hole” plot shape is not the only one with a nadir in the middle: Vonnegut’s “Boy meets Girl” plot shape also has its greatest moment of negativity in the middle of the story.
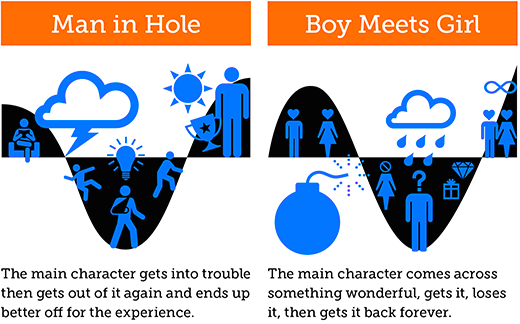
As a result, if we only at the lowest point only and consider rises or falls on either side irrelevant, as Matt does, then we can’t tell the differences between them. It’s also interesting to note that the foundation shape for Portrait of the Artist rises, falls, rises again, and falls again, which makes it much closer to a “Boy meets Girl” shape than the “Man in a Hole” that Matt continuously insists it is (though neither shape should have that final fall at the end). In short, the foundation shapes don’t just “miss some of the subtitles [sic]” in the data; they flat out distort it and introduce errors that in places make the foundation shape the opposite of the emotional trajectory.
Matt also objects to my using Syuzhet’s default value of 3 as the cutoff for the low pass filter for my graphs, stating that, as it is a “user tunable parameter,” it can be raised to reduce the ringing artifacts. I generated the examples with the default value because it is the number he used in his clustering, from which he concluded that there are only 6 or 7 plot shapes. Raising that number isn’t really a solution for two reasons: 1. It wouldn’t eliminate the ringing (ringing artifacts happen with any low-pass filter, though they’ll be smaller with higher cutoffs); and 2. It would require redoing all the clustering that led to these “archetypal” shapes, as the number and type of common plot shapes will likely be dramatically different with more terms.
Overall, there is no point in “seek[ing] to identify an ‘ideal’ number of components for the low pass filter,” because the low-pass filter is a poor choice for this resampling application: Gaussian blurring and a simple window average would be more successful because they would simplify the data without distorting it. In an earlier blog post, Matt justifies the low-pass filter instead of a simple window average (which he has already implemented as get_percentage_values) by claiming “You cannot compare [the results of get_percentage_values] mathematically because the amount of text inside each percentage segment will be quite different if the novels are of different lengths, and that would not be a fair comparison.” This suggests that he misunderstands the mathematics behind the low-pass filter he has implemented, because this statement is just as true of low-pass filtering as it is of get_percentage_values: each value in the result is a weighted average of the original values, and more text is averaged per data point in a longer novel than in a shorter one. If this really were an unfair comparison, then the entire Syuzhet project would be hopeless.
On Validation in the Humanities
The errors with Syuzhet and this whole debate about whether or not it works relate to a larger question about validating a tool in the Humanities, which Andrew Piper touched on in his recent blog post: “Validation is not a process that humanists are familiar with or trained in. We don’t validate a procedure; we just read until we think we have enough evidence to convince someone of something.” Unfortunately, “read[ing] until we think we have enough evidence” doesn’t work with programming and science: programmers and scientists must actually design tests to make sure that the tools we build work as advertised. Building tools for distant reading therefore involves at least two types of validation: the first type requires making sure the tool works as expected, and the second type, possible only once the first type of validation works, requires analyzing the results of the tool to come up with new theories about history, literary history, or plot, or whatever the primary subject matter is for a given corpora. My blog posts have focused on the first type of validation: I have provided some sample tests where Syuzhet clearly fails, which means that we need to go back to fix the tool before we can take its output seriously and analyze it.
Fortunately, coming up with a way to perform the first type of validation for a Humanities tool is not as dire a problem as Andrew Piper suggested when he wrote “We can’t import the standard model of validation from computer science because we start from the fundamental premise that our objects of study are inherently unstable and dissensual.” As it turns out, the Humanities are not unique in studying the liminal or the multifaceted: many subfields of computer science struggle with “unstable” data all the time, from image processing to machine learning. True sentiment analysis scholars work on this problem: they acknowledge that words are polysemous, that language is nuanced and ambiguous, and that everyone reads texts differently. That’s why they use human-annotated corpora of texts, from which they can estimate how an “average” reader evaluates documents, to measure how well their algorithms approximate that “average” reader. We can actually learn a lot about addressing this problem by collaborating with our colleagues from outside the Humanities.
This brings me to my final point: Digital Humanities is best when we collaborate. As Humanists, we’ve been very well trained in our particular field (or fields, if we double-majored once upon a time), but we often haven’t been trained in things like statistics, sentiment analysis, or signal processing. We’re used to researching a wide variety of subjects, and that can take us pretty far, but we’re unlikely to fully understand all the nuances of the fields we try to learn on our own, especially if they usually require a PhD in physics or math. A quick conversation with a colleague in a different field goes a long way towards finding exciting solutions to confounding problems, but it’s not going to be enough to fully explain things like ringing artifacts or Fourier transforms. The only way to make sure that we’re not introducing problems we could never have anticipated with our limited knowledge is by assembling a team of experts. Before I posted my first response to Syuzhet, I sought input from people in a wide variety of fields—electrical engineers, software developers, mathematicians, and machine learning specialists—to make sure my critiques were valid, and I credited them in my post. Without collaborative teams comprised of scholars from a wide variety of fields, digital humanities scholarship will continue to be plagued by easily avoidable errors.
NOTES:
[1] While Ted Underwood has claimed that Syuzhet is entirely exploratory and no scholarly claims have been made, I will take Matt at his word and respond to the thesis he has posited in several blog posts and news articles.
[2] Matt Jockers informed me that he prefers to go by his first name, so I will happily oblige in this post.
